Abstract
To operate in the physical world, embodied agents must perceive their environment in an "always-on" fashion, selectively accessing the most informative sensors to balance energy constraints and task accuracy. Despite its importance for resource-constrained devices, energy-aware perception remains under-explored, with most prior work assuming unlimited compute. To address this, we introduce Ego-METAS: the first Egocentric online Multimodal Energy-efficient Temporal Action Segmentation benchmark. Ego-METAS provides a unified testbed of more than 100 hours of untrimmed egocentric video from EgoExo4D, CMU-MMAC, and CaptainCook4D, spanning 5 modalities (RGB, audio, gaze, IMU, and monochrome camera). We formulate an online temporal action segmentation task where models must dynamically select which sensors to activate at each timestep while strictly adhering to hardware-representative energy budgets. Alongside the benchmark, we release unified splits, cleaned annotations, pre-extracted features, and a diverse suite of baseline routing policies. Our evaluations show that optimal routing is highly scenario-dependent, and that existing policy-learning methods—designed primarily for trimmed clips—struggle to adapt to continuous, untrimmed environments. However, even simple dynamic fusion of complementary modalities (e.g., via random routing) proves critical for balancing predictive accuracy against strict energy budgets. Ultimately, Ego-METAS provides a standardized foundation to develop robust, cost-aware policies for autonomous, always-on embodied AI.
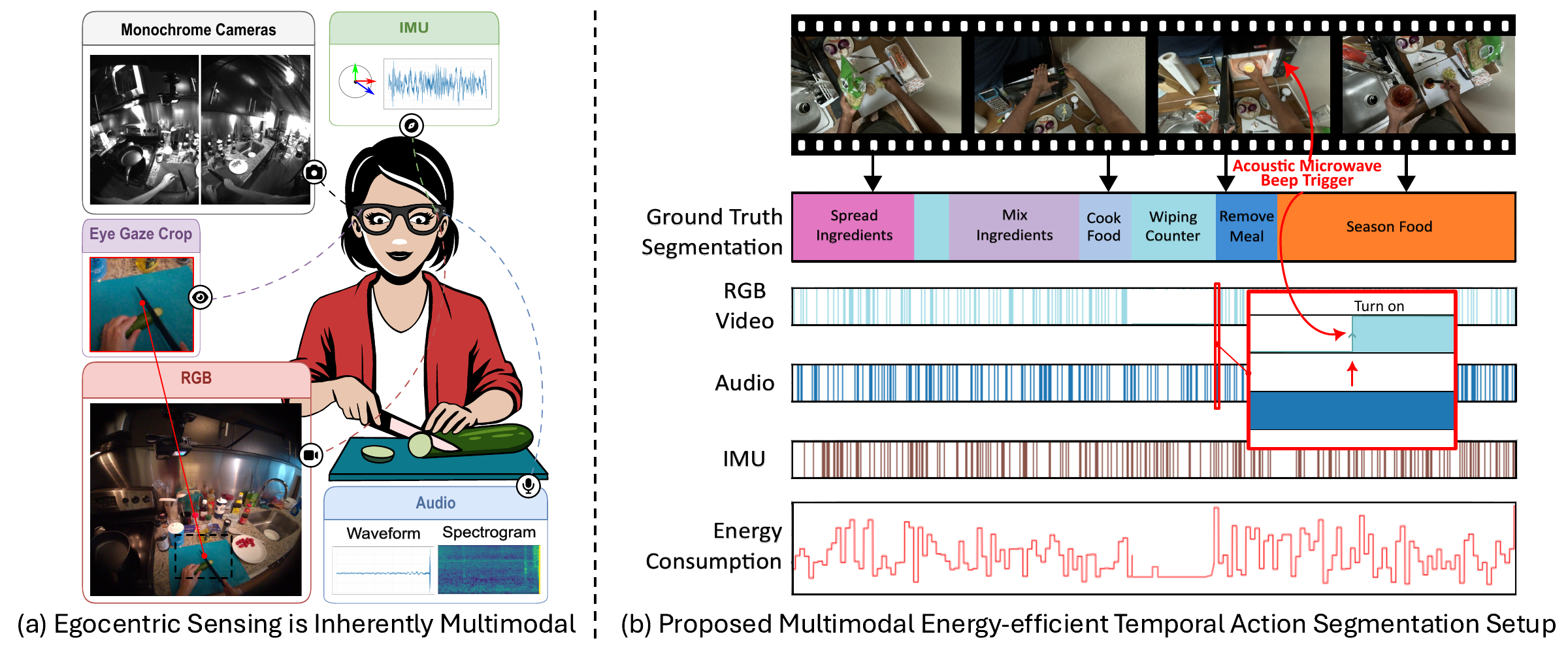
Benchmark
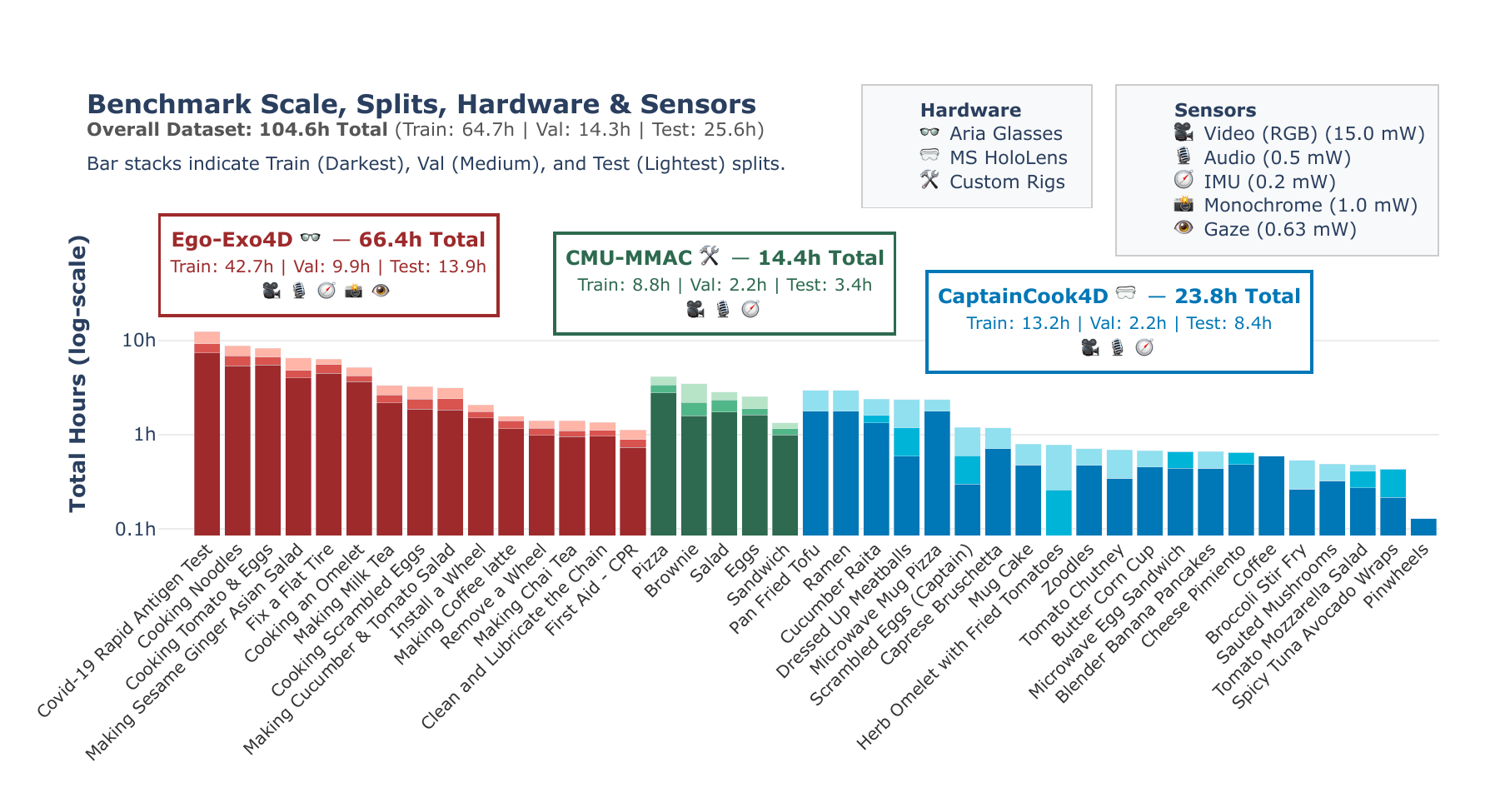
Ego-METAS is the first benchmark to target untrimmed, continuous action segmentation across diverse wearable platforms. To resolve historical inconsistencies in prior datasets, we rigorously revise existing annotations and establish a unified evaluation protocol that moves beyond standard task accuracy, allowing us to quantitatively assess model performance against explicit energy consumption limits and strict operational budgets. Furthermore, to accurately reflect the physical realities of wearable systems, we curate a principled set of modalities, ranging from full RGB streams to energy-efficient grayscale images and gaze-centered crops, and provide concrete estimates for their respective acquisition, memory, and processing costs.

At each timestep, a routing policy decides which sensors to activate next. Active modalities incur capture, memory, and computation costs. The goal is to maximize temporal action segmentation performance while respecting a strict energy budget.
Baseline Policies
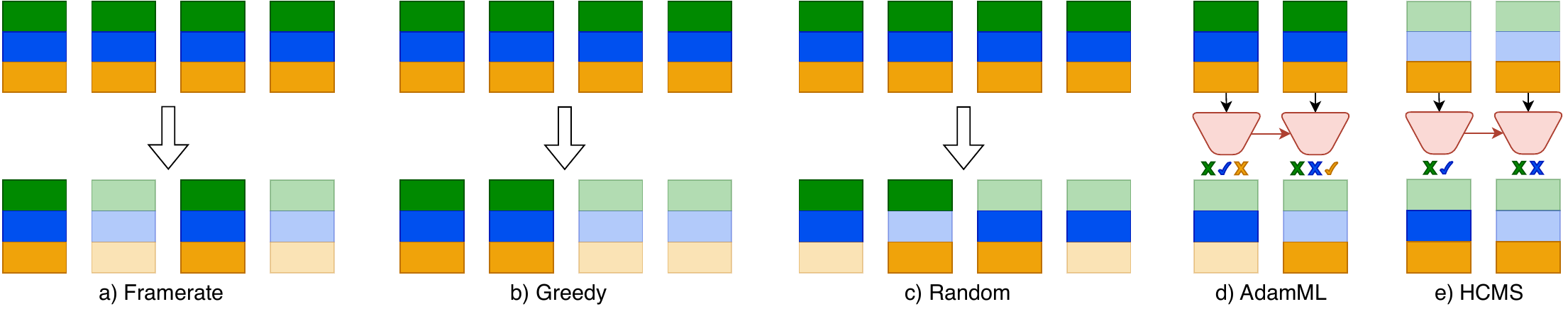
- Frame Rate: Fixed sampling rates for one or more modality combinations.
- Random: Per-timestep modality dropout applied during training (DT) and inference (DI).
- Random Cost-Aware: Random routing weighted to drop expensive modalities more often while keeping all modalities sampleable.
- Greedy: Activates all modalities until reaching the predetermined energy budget per second.
- AdaMML: Adaptive multimodal learning with differentiable modality routing.
- HCMS: Hierarchical Cost-aware Model Scheduling.
Results Summary Tables
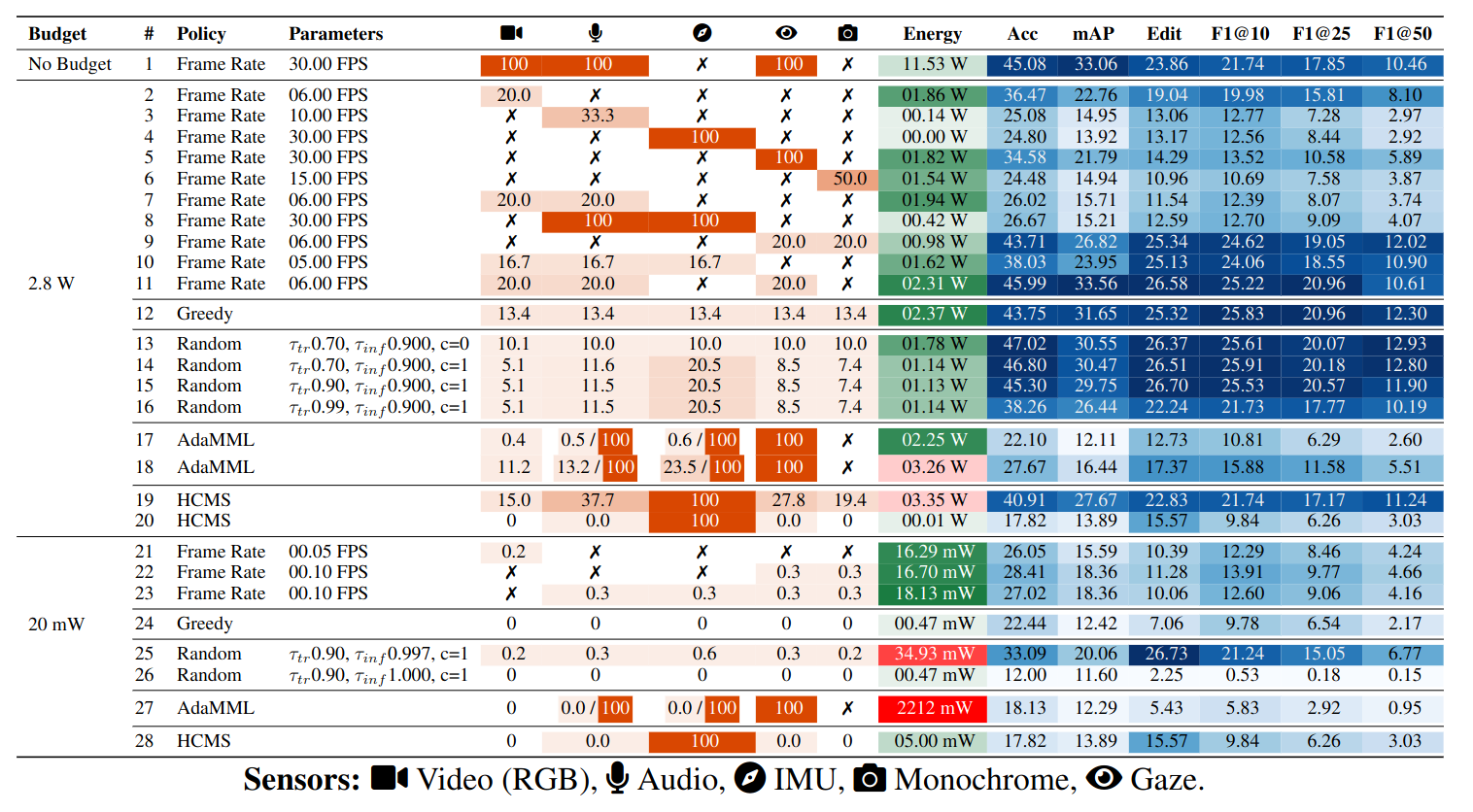
The tables below summarize the main energy-accuracy operating points across EgoExo4D, CMU-MMAC, and CaptainCook4D. They compare static frame-rate baselines with random, cost-aware, greedy, AdaMML, and HCMS routing policies under the same benchmark protocol.
EgoExo4D Dataset
CMU Multiplex Dataset
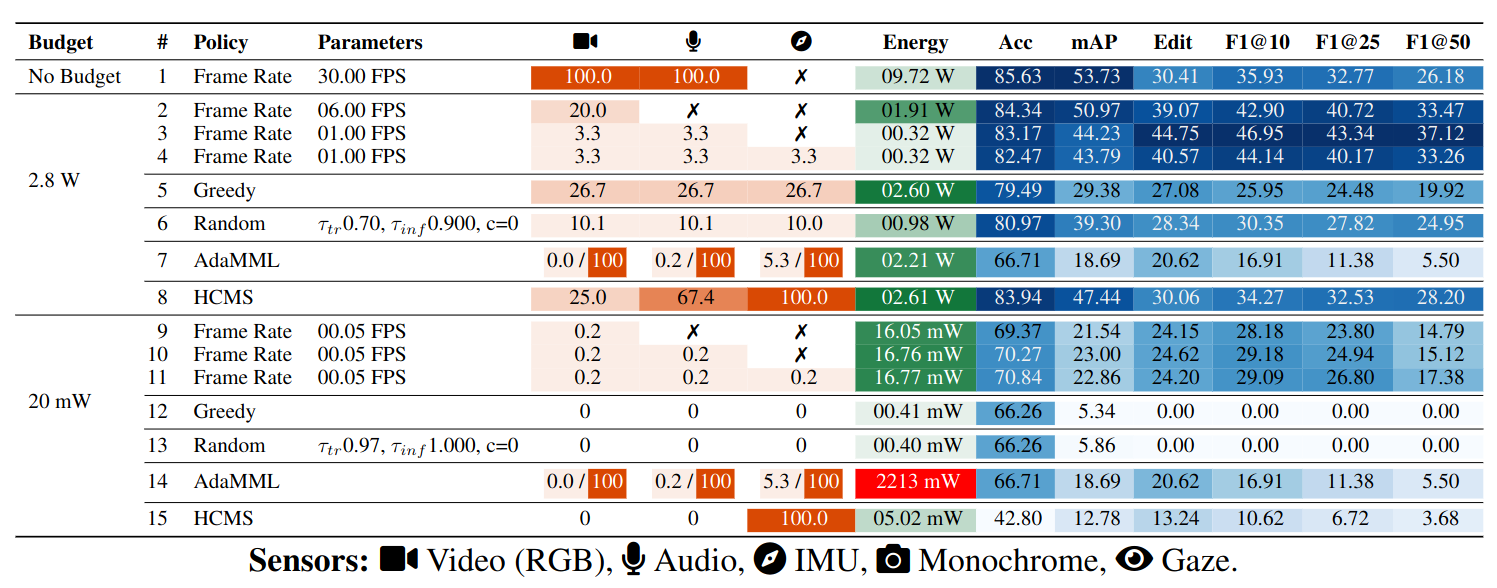
CaptainCook Dataset
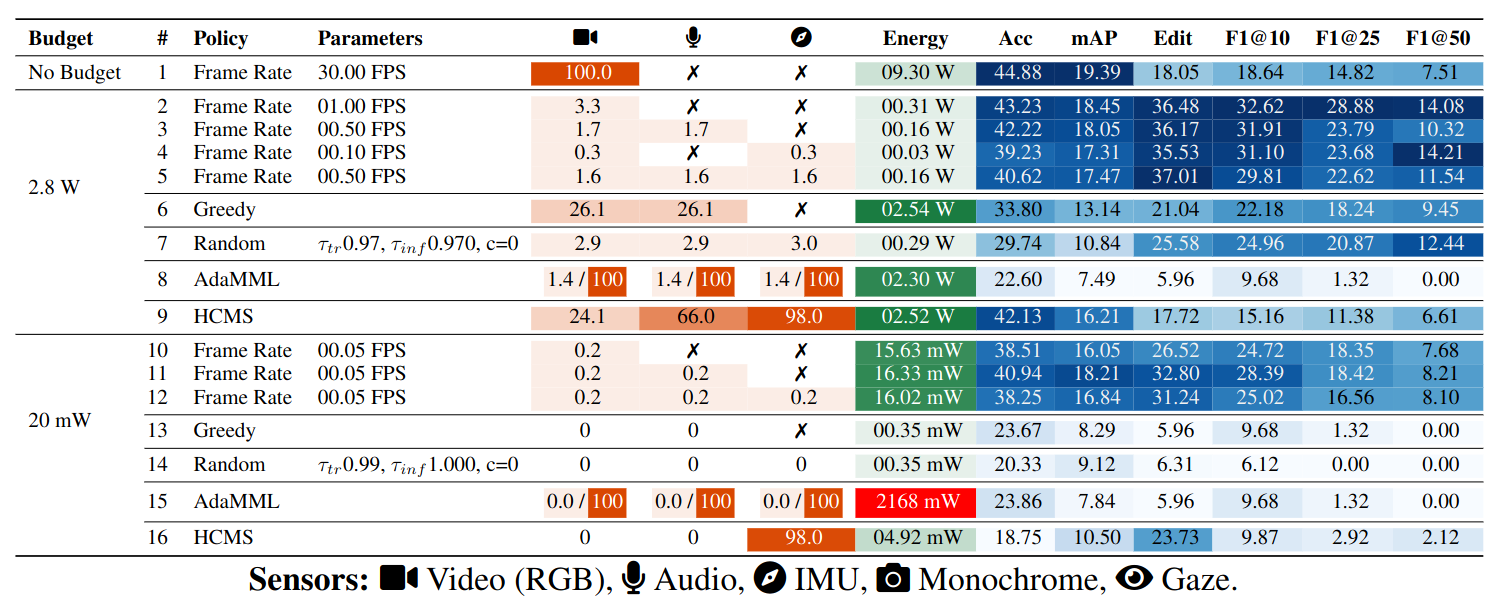
The results show that the best routing strategy is strongly scenario-dependent: dynamic policies often help, but existing learned policies designed for trimmed clips struggle in continuous untrimmed settings.
Results: Accuracy vs Energy Trade-off
Explore the interactive graphs below showing the relationship between model accuracy and energy consumption for different datasets. Hover over data points to see detailed information about each model variant.
Key Metrics
- DT/DI: Dropout probability during Training and Inference (for Random policies).
- FPS: Frames per second used in Frame Rate policies.
- Threshold: Decision threshold for HCMS and AdaMML policies (higher = less modalities selected).
- Energy Budget: Target energy constraint for Greedy policy.
- Energy: Average energy consumption per second of video.
- Accuracy (%): Model accuracy on action anticipation task.
The dashed vertical lines indicate considered energy thresholds: 20 mJ (efficiency boundary) and 2800 mJ (high-energy region).
EgoExo4D Dataset
CMU Multiplex Dataset
CaptainCook Dataset
Qualitative Results
Qualitative examples reveal failure modes that are difficult to capture from aggregate metrics alone. In the static examples below, AdaMML often over-commits to low-cost sensors such as IMU, even when visual evidence is necessary to segment the action correctly. This can produce severe temporal segmentation errors and, in some cases, a collapsed routing behavior where RGB and audio are persistently deactivated.
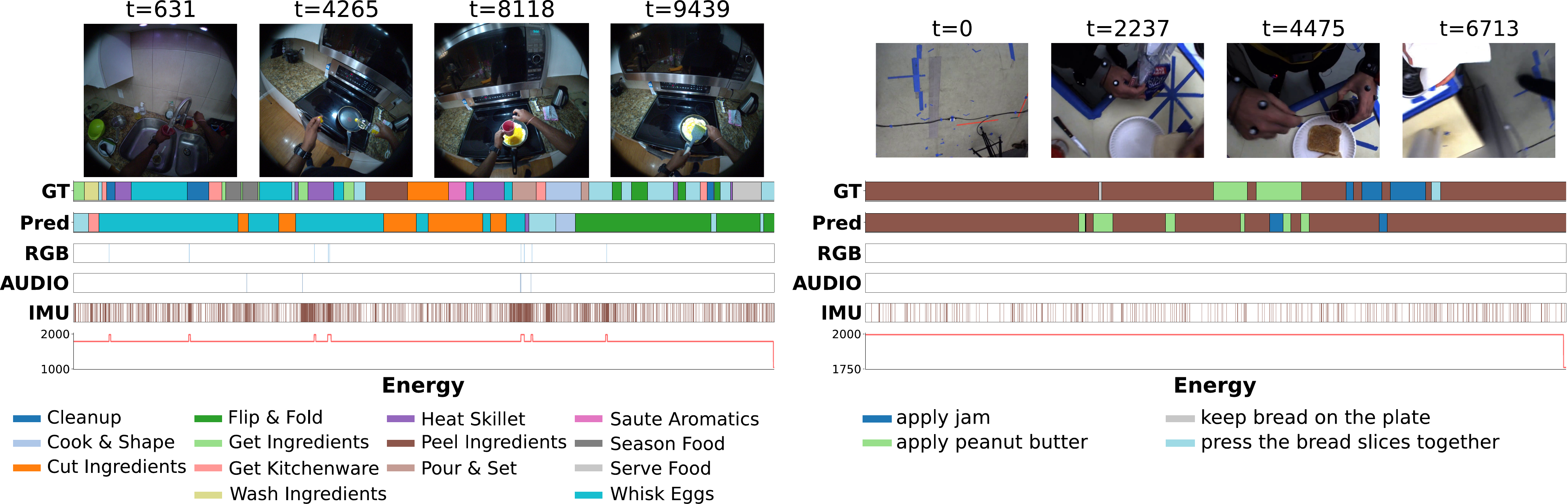
The videos provide frame-level examples of how routing decisions evolve over time. Modalities shown in color are active at the current timestep, while gray modalities are inactive. For the AdaMML example, the visualization shows the policy output; its energy accounting still includes the overhead of modalities that must remain available for routing decisions, such as gaze, audio, and IMU.
Cite As
@article{santos2026egometas,
title={Ego-{METAS}: Egocentric online {M}ultimodal {E}nergy-efficient {T}emporal {A}ction {S}egmentation benchmark},
author={Santos-Villafranca, Maria and Bermudez-Cameo, Jesus and Perez-Yus, Alejandro and Farinella, Giovanni Maria and Furnari, Antonino},
journal={arXiv preprint arXiv:2606.02246},
year={2026}
}